Showing Technology posts. Go back home.
-
Back to the Browser - A JavaScript Workflow for UNIX Nerds
When Apple announced Mac OS X Lion, their tagline was “Back to the Mac” as they were bringing some features from iOS into the desktop-oriented Mac OS. In the JavaScript world, a similar thing has happened: innovations in the Node.js space can be brought back to the browser. These innovations have made JavaScript development faster and cleaner with command-line tools and the npm packaging system.
-
Split XML files with `sgrep`, a classic UNIX utility from 1995
sgrepis better thansplitorcsplitfor breaking up XML files by element – you can even use it to create a constant-memory streaming “parser.”$ sgrep -o "XXXSTART%rSTOPXXX" '"<TourismEntity" .. "</TourismEntity"' transmission_file.xml XXXSTART<TourismEntity> <State>New York</State> <Saying>I♥NY</Saying> </TourismEntitySTOPXXXXXXSTART<TourismEntity> <State>Virginia</State> <Saying>Is For Lovers</Saying> </TourismEntitySTOPXXXXXXSTART<TourismEntity> <State>Wisconsin</State> <Saying>America's Dairyland</Saying> </TourismEntitySTOPXXX(see below for why that output is useful)
-
Upsert for MySQL, PostgreSQL, and SQLite3 (and Ruby)
Our
upsertlibrary for Ruby gives you NoSQL-likeupsertfunctionality in traditional RDBMS databases. How?- MySQL’s native
INSERT ... ON DUPLICATE KEY UPDATE - PostgreSQL’s canonical
CREATE FUNCTION merge_db - SQLite3’s
INSERT OR IGNOREplus a trailingUPDATEstatement
50%–80% faster than ActiveRecord
New in 0.4.0: When used in PostgreSQL mode, database functions are re-used, so you don’t have to be in batch mode to get the speed advantage.
You don’t need ActiveRecord to use it, but it’s benchmarked against ActiveRecord and found to be up to 50% to 80% faster than traditional techniques for emulating upsert:
# postgresql (pg library) Upsert was 78% faster than find + new/set/save Upsert was 78% faster than find_or_create + update_attributes Upsert was 88% faster than create + rescue/find/update # mysql (mysql2 library) Upsert was 46% faster than find + new/set/save Upsert was 63% faster than find_or_create + update_attributes Upsert was 74% faster than create + rescue/find/update Upsert was 28% faster than faking upserts with activerecord-import (which uses ON DUPLICATE KEY UPDATE) # sqlite3 Upsert was 72% faster than find + new/set/save Upsert was 74% faster than find_or_create + update_attributes Upsert was 83% faster than create + rescue/find/update(run the tests on your own machine to get these benchmarks)
- MySQL’s native
-
Graphite and statsd – beyond the basics
The Graphite and statsd systems have been popular choices lately for recording system statistics, but there isn’t much written beyond how to get the basic system set up. Here are a few tips that will make your life easier.
-
Analyze CREATE TABLE SQL with pure Ruby
You can use the new create_table library to analyze and inspect CREATE TABLE statements (what is the primary key? what are the column data types? what are the defaults?) You can also generate SQL that works with different databases.
>> require 'create_table' => true >> c = CreateTable.new(%{ CREATE TABLE employees (employeeid INTEGER NOT NULL, lastname VARCHAR(25) NOT NULL, firstname VARCHAR(25) NOT NULL, reportsto INTEGER NULL); }) => #<CreateTable> >> c.columns.map(&:name) => ["employeeid", "lastname", "firstname", "reportsto"] >> c.columns.map(&:data_type) => ["INTEGER", "CHARACTER VARYING(25)", "CHARACTER VARYING(25)", "INTEGER"] >> c.columns.map(&:allow_null) => [false, false, false, true] -
How to parse quotes in Ragel (and Ruby)
The key to parsing quotes in Ragel is ([^’\] | /\./)* as found in the
rlscanexample. Think of it as ( not_quote_or_escape | escaped_something )*. -
Simple, clean reports in Ruby
Our
reportlibrary for Ruby is the shortest path betweenmysql> select * from employees; +----+------------+-----------+---------+------------+---------+ | id | first_name | last_name | salary | birthdate | role | +----+------------+-----------+---------+------------+---------+ | 1 | Deirdre | Irish | 45000 | 1960-09-10 | Liaison | | 2 | Gregor | German | 16000.5 | 1950-09-09 | Tech | | 3 | Spence | Scot | 5000 | 1955-12-11 | Joker | | 4 | Vincent | French | 8000.99 | 1947-04-17 | Fixer | | 5 | Sam | American | 16000.5 | 1930-04-02 | Planner | +----+------------+-----------+---------+------------+---------+and simple, clean reports like
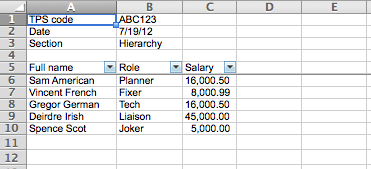
-
The Green Button that could have been
What’s the first step in discovering efficiency opportunities? Data, data, data. That’s what we always say here at Brighter Planet, where we’re trying to compute our way to a more hopeful environmental future.
So I’m sure it won’t surprise you when I say that the key to the energy challenge also starts with data: how much we’re using and when and where we’re using it. Which makes it all the more poignant to write this critique of the much-lauded Green Button program, which ostensibly is all about opening up energy data.
The truth is that Green Button, as a government advocacy program, has not succeeded in unleashing the gold rush of energy efficiency magic we know is locked up in the heads of entrepreneurs. Developers aren’t building apps, consumers aren’t using them, and utilities aren’t playing ball. Frankly it’s hard to blame them. Luckily there’s a better way to do Green Button, using modern technology to truly empower energy consumers in a lasting, meaningful way. But first . . .
-
A Deep Dive Into the New Automobile Emitter
We’ve made some exciting changes to our automobile emitter. Let’s take a look!
-
Striving for a great API client
I wanted to take a moment to share some of the principles and technologies we used to build client libraries for our CM1 web service. As developers, we know how frustrating it can be to learn a new API and we keep that in mind as we design our client libraries to spare others of the same frustration.
-
Writing XLSX from Ruby
Our
xlsx_writerlibrary for Ruby lets you create spreadsheets compatible with Microsoft Office 2007 Excel and above.Features
- Essential cell types: general, currency, date, integer, float (decimal)
- Standardized formatting: Arial 10pt, left-aligned text and dates, right-aligned numbers and currency
- Auto-fit to contents: always enabled
- Autofilters: just give it a range of cells
- Header and footer print styles: margins, arbitrary text, page numbers, and vector logos (.emf)
-
Vote for Sparkwire!
We want YOU to vote for Sparkwire, our Apps for Energy challenge entry. It allows any app to access your Green Button data without you having to download it yourself from your utility.
Green what?
Green Button is a new standard being led by the Department of Energy which allows anyone to download their energy usage data from their utility. The DOE started the Apps for Energy contest in April to help drive use of the new standard. Currently, 15 utilities serving 27 million homes have committed to providing Green Button downloads. With this data, there are many ways apps could help us save energy: think targeted conservation tips to comparisons with neighbors to verification of energy-efficiency investments to rewarding greener behavior. Many companies and individuals have already developed great new energy apps to help all of us make sense of this data, reduce our energy use, and save money.
There is a catch, though: for these energy apps to work well, they have to be able to get our Green Button data without us having to log in and download the data every month/hour/minute. Our experience in helping individuals reduce their environmental impact has taught us that removing barriers to entry is critical. So we created our own app, Sparkwire, to easily share your Green Button data with other apps. You just provide Sparkwire with your utility site login and it does the rest. Any app connected to Sparkwire can pull in your latest data without any additional log-in or download. Don’t worry, your login info is encrypted and can only be used when an app you authorize requests access. This video demonstrates everything.
Please give us your support by voting today (and every day thereafter :)) at challenge.gov.
-
Write code, save the planet
We’re happy to announce greendreams, a compendium of environmental APIs for all the Cleanweb hackers out there.
 {.wide}
{.wide}Currently we have 6 APIs listed, but of course the more the merrier, so please fork away and add your favorites. Big thanks go out to Genability, GoodGuide, NREL, EPA, and AMEE for helping out with the first crop of APIs.
-
Introducing Prospect
Have you ever wanted to add environmental impact data to your site? You’ve probably been too busy or don’t have the resources to have a developer integrate your site with an API like CM1. If so, we have good news for you! With our new service, Prospect, you can add the power of CM1 (carbon footprints, resource usage, etc.) to your website with a minimal amount of coding! If you can edit HTML on a web page, you can be up and running with Prospect in minutes.
-
How to install mosh on Amazon EC2
Here’s how to install mosh on Amazon EC2 instances:
-
Beware of String#hash being used for cache keys...
Every process will have a different hash value for the same string, so cache keys based on
String#hashwill not work as expected!1.9.3-p0 :001 > 'test'.hash => 240227015057187339 1.9.3-p0 :002 > 'test'.hash => 240227015057187339But in another IRB session:
1.9.3-p0 :001 > 'test'.hash => -2779337368972820904 1.9.3-p0 :002 > 'test'.hash => -2779337368972820904All calls to plain vanilla
Object#hashhave the same problem. It turns out it’s intentional… -
Cleanweb Hackathon NYC
We’re back from the Cleanweb Hackathon! It was a great weekend of meeting entrepreneurs in the clean tech space, joining forces with some of New York’s finest hackers, and hanging out at NYU’s Interactive Telecommunications space.

Image credit: @greenskeptic, Instagram
-
Join us at Cleanweb Hackathon NYC this weekend
We’re psyched to be sponsoring—and participating in—this weekend’s Cleanweb Hackathon in New York City.
 {.wide}
{.wide}As usual, we’ll be holding a series of Healthy Hacker activities over the course of the weekend. (Above is a shot of the Healthy Hacker yoga class we held during EcoHackNYC in November.)
-
Fuzzy match in Ruby
Our
fuzzy_matchlibrary for Ruby can help link (cross-reference) records across data sources—for example, match up aircraft records from the Bureau of Transportation Statistics and the Federal Aviation Administration:
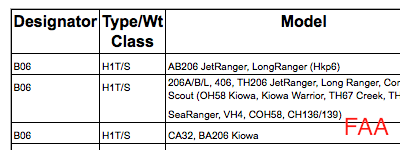
-
Why the Brighter Planet API uses POST
Have we really created a RESTful web service? If so, why are we specifying that users send POST requests to get calculations? I asked this question to the rest of my team and a lively debate ensued among us.
-
Building snowflakes: the tech behind our holiday card
Last week we posted our 2011 holiday card, which has seen quite a bit of traffic since. There’s actually some pretty interesting new technology under the hood, so I thought I’d put together this behind-the-scenes blog post for anybody who’s interested.
-
Building queries for fun and profit
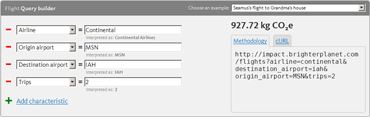
The primary way to experiment with CM1 is to hit the API directly—either with code, a tool like cURL, or with our CM1 console. But sometimes it’s just easier to play around in a browser, so today we’re rolling out a Query Builder feature for each of our impact models. Details after the jump.
-
Green Developers: a penny for your thoughts
Brighter Planet is working on a paper outlining the growing ecosystem of green apps, and if you are a software developer who’s worked in this area, we want your perspective. By sharing your thoughts about your own apps and the broader movement, you’ll help inform our best practices for engaging developers and could get a bump by having your app covered as a case study in the paper.
-
Carbon Nation
 {.wrapped} Here’s a guest post from our good friend and former Planeteer Carolyn Barnwell, who’s now involved, among other things, in Carbon Nation, an important new documentary on climate change. Without further ado . . .
{.wrapped} Here’s a guest post from our good friend and former Planeteer Carolyn Barnwell, who’s now involved, among other things, in Carbon Nation, an important new documentary on climate change. Without further ado . . .Sometimes the best way to promote clean energy is to ignore climate change and focus on things like jobs, money and national security. Carbon Nation is a solutions-based, non-partisan documentary that illustrates why it’s smart to be a part of the new, low-carbon economy. It just came out on DVD and Video On Demand! The movie’s message dovetails perfectly with the trail-blazing carbon data integration that Brighter Planet is doing.
-
Join us at the EPA Apps Forum
Update: free registration deadline extended to October 28!
Mark your calendars for the EPA’s Apps for the Environment Forum in Arlington, Virgina on November 8. Brighter Planet co-founder Andy Rossmeissl is a featured speaker at the event, in addition to EPA Administrator Lisa P. Jackson and others.
RSVP now (deadline is
TuesdayOctober 28) or read on for more details. -
Stamp PDFs with Prawn and Pdftk
In order to generate PDFs with a standard template, Brighter Planet uses a combination of Prawn and Pdftk.
First, we generate the content pages:


-
Presentation at Strata NYC
Last week I made a presentation at Strata NYC, the O’Reilly conference on Big Data. The presentation (embedded below) is in Ignite style, so it’s a total of five minutes long.
-
Hipmunk, Amtrak, and sustainability: context is everything
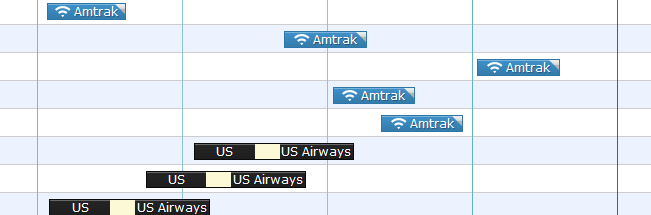 {.wide}
{.wide}Today Hipmunk announced that it has added Amtrak trains to flight search results. Reactions have been positive (e.g. VentureBeat, Gadling, Tnooz) and have focused on the lower prices and oftentimes better schedules that trains can offer travelers versus planes on certain routes.
But we like it for a much different reason: it’s a triumph of sustainability.
-
2 easy ways to join the EPA's app challenge
As part of Administrator Lisa Jackson’s push to leverage open government data in meeting the its seven priorities, the EPA is hosting a great competition that challenges developers to build applications drawing on publicly available EPA data. The Apps for the Environment challenge is a call for new tools that help individuals and communities address environment and public health issues, with the top apps winning a year of promotion on the EPA website. Submissions are open for another three weeks.
Haven’t submitted anything yet? Using free Brighter Planet tools, you can get started on your own app super quick.
-
New in CM1: carbon equivalents
Something we have learned over our 5+ years at Brighter Planet is that, in certain cases, carbon impact can be described most powerfully when it is given in “real life” units. That is, instead of saying a flight has a footprint of 1,045.77 kg CO2e, you say it’s like adding 69 cars to the road for a day.
We released a new feature to CM1 a couple of weeks ago that provides dozens of “equivalents” like this with every JSON and XML response we deliver (example). Reactions so far have been positive, so we’re now marking the feature as public beta.
The conversions are part of our new open-source co2_equivalents library—check out the source for details, including complete citations.
-
Tronprint Updates
This week, some of our servers that were running Tronprint started having DNS problems. Tronprint was unable to connect to our MongoHQ database and our sites crashed. We’ve updated the Tronprint gem to handle connection issues to any database. In the case of a lost connection or a problem saving statistics, Tronprint will simply keep running and wait for the connection to become available again. This means that data could be lost if a connection is never recovered and the application process quits. However, the connection failure will not affect the operation of your site.
We’ve also created a Twitter account to keep you updated on new versions and features.
-
Stream parser with Ragel and Ruby
You can use Ragel to make simple stream parsers in Ruby. By “stream parser,” I mean one that reads in files a chunk at a time instead of all at once—thereby keeping memory use constant.
-
A Pattern for JavaScript Events
While working on Hootroot and Careplane, I found myself getting frustrated with the way I was having handling events. Over time, however, I stopped fighting the language and learned a pattern that I believe is easiest to test and read.
-
Tronprint is Now in Public Beta
Our Tronprint plugin for Heroku, which measures your cloud app’s carbon footprint, has just graduated from private beta to public beta! This means anyone with a Heroku account can try it out. Of course, if you don’t use Heroku, you can still install the Tronprint gem in your existing Ruby or Rails application.
We’d love to hear your feedback, so feel free to tweet or email us.
-
Introducing Bombshell: custom interactive consoles for your Ruby libraries
One of the cool features of
carbon, the Ruby library for our CM1 web service, is its built-in interactive console for experimenting with the service. At Brighter Planet we usecarbon’s console all the time to construct one-off calculations and perform simple analyses. -
Resque, the rand() method, and Kernel.fork
We had a seemingly impossible number of tmpdir collisions once we switched our reference data web service from DelayedJob to Resque.
The culprit was calling
rand()in worker processes that are forked off the main process by Resque:$ irb > Kernel.fork { puts rand.to_s } 0.536506566371644 > Kernel.fork { puts rand.to_s } 0.536506566371644 # the same > Kernel.fork { puts rand.to_s } 0.536506566371644 # the sameDon’t forget to call
srand!$ irb > Kernel.fork { srand; puts rand.to_s } 0.232438861240513 > Kernel.fork { srand; puts rand.to_s } 0.363543277594837 > Kernel.fork { srand; puts rand.to_s } 0.000133387538081786Now it’s fixed in the remote_table gem via this commit.
-
Carbon.js
Lately, I’ve been working on a Google Maps mashup that calculates CO2 emissions for automobile, bus, and rail trips. Since Google Maps has such a great JavaScript API, I decided to write the application almost entirely in JavaScript. Thus, Carbon.js was born!
-
What you should know about mysql2 memory usage
If you’re using mysql2, you should be aware of a memory usage issue:
# mysql2 gem - no way to avoid using a lot of memory if you're streaming a lot of rows client = Mysql2::Client.new(:host => "localhost", :username => "root") results = client.query("SELECT * FROM users WHERE group='githubbers'") # mysql gem - keep memory usage flat if you're streaming a lot of rows dbh = Mysql.init dbh.connect "localhost", "root" dbh.query_with_result = false dbh.query("SELECT * FROM users WHERE group='githubbers'") results = dbh.use_result -
Virtual servers, real impact
Last week we announced Tronprint, our Ruby library for measuring an application’s carbon footprint in real time. There’s a subtlety to the way that my colleague Derek designed Tronprint that didn’t hit me for a while: as a piece of monitoring software it’s “inside-out” rather than “outside-in.” It’s a simple distinction that’s going to let us continue to address sustainability in this new era of cloud computing.
-
Exploring data in partnership with Google
Google’s DSPL and Public Data Explorer help us improve our reference data web service by visualizing it. Working with Jürgen Schwärzler, a statistician for Google, we laid the foundation for an automobile industry dataset:
-
Tronprint: Measure the footprint of your cloud application
One of the major factors contributing to an organization’s sustainability, especially for web application companies, is the carbon footprint associated with IT operations. Gartner Research has estimated that the IT sector accounts for 2% of global greenhouse gas emissions and that, “despite the overall environmental value of IT, Gartner believes this is unsustainable.”
-
Bringing carbon calculations to TripIt
It’s a privilege to be posting here on Safety in Numbers, and particularly exciting to do so as Brighter Planet’s first Developer Fellow. I was an early Brighter Planet cardholder and have watched the team closely, so it’s great to get a chance to work with them.
-
Welcome Matt Colyer, our second Developer Fellow
 Close on the heels of our first fellow, we’re now super happy to welcome our second, Matt Colyer. We’re huge fans of his smartermeter project and definitely want to see more like it for other energy providers. smartermeter’s roadmap includes carbon calculation (powered by our CM1 service) and a UI for PG&E customers.
Close on the heels of our first fellow, we’re now super happy to welcome our second, Matt Colyer. We’re huge fans of his smartermeter project and definitely want to see more like it for other energy providers. smartermeter’s roadmap includes carbon calculation (powered by our CM1 service) and a UI for PG&E customers. -
Introducing our Developer Fellowship program: real financial support for important software projects and their developers
We use a whole lot of open source software at Brighter Planet—Ruby, Rails, and Vagrant, just to name a few. A few months ago, we decided that we wanted to take a cue from EngineYard’s OSS Community Grant program and provide meaningful financial support to the volunteer developers of important software projects.
We’re now happy to announce the Brighter Planet Developer Fellowship.
Calling all developers: Do you maintain software critical to the GitHub-EngineYard-AWS ecosystem? Working on a scientific library for Ruby? Have an idea for a clever way to use CM1 carbon calculations? Curate an authoritative dataset? We can support and accelerate your good work. Please get in touch (#brighterplanet on Freenode, @brighterplanet on Twitter, or brighterplanet on GitHub).
 We’re thrilled to welcome our first Developer Fellow, Scott Bulua. Scott’s building a plugin for TripIt that tracks the carbon footprints of users’ itineraries using calculations powered by our CM1 web service. We’ll be hearing from Scott on this blog from time to time as he develops his tool; check back for updates.
We’re thrilled to welcome our first Developer Fellow, Scott Bulua. Scott’s building a plugin for TripIt that tracks the carbon footprints of users’ itineraries using calculations powered by our CM1 web service. We’ll be hearing from Scott on this blog from time to time as he develops his tool; check back for updates.Interested? The Developer Fellowship accepts unsolicited applications, so visit the Fellowship page for details.
--> -
The wonderful convenience of Earth
When I was whipping up Yaktrak I needed to get a (richly annotated) list of zip codes into the app. This is a familiar problem for web app developers: what’s the easiest way to get auxiliary data from canonical sources loaded and ready to use?
-
Announcing our new parcel shipment model
We just released the initial version of a new carbon model for package shipping. It’s designed to help businesses and software developers in the logistics, retail, and IT fields track carbon alongside the other parcel-level data they’re already managing in their existing software systems. You can find the press release here.
-
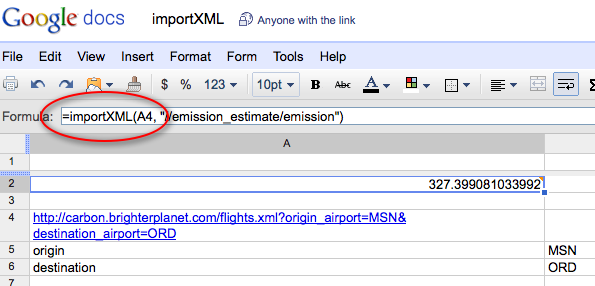
Using web services from Excel
Of course it’s easy in Google Docs…
Still, I got pretty excited when I saw this for the first time:
-
How we replaced ParseTree in Ruby 1.9
Like many Ruby shops, we took for granted ParseTree’s ability to show the source code of pretty much any object. As previously explained, however, ParseTree doesn’t work with Ruby 1.9.2. We fixed the problem by using sourcify.
## DOESN'T WORK IN RUBY 1.9 gem 'ParseTree', :require => false require 'parse_tree' require 'parse_tree_extensions' ## WORKS IN RUBY 1.9 gem 'sourcify' gem 'ruby_parser' gem 'file-tail'In particular, we replaced ParseTree’s Proc#to_ruby with sourcify’s Proc#to_source.
## The old ParseTree way proc.to_ruby ## The sourcify way - but raised NoMatchingProcError or MultipleMatchingProcsPerLineError proc.to_source ## The sourcify way - giving :attached_to a symbol to help it find the correct Proc proc.to_source :attached_to => :quorumWe needed to pass the :attached_to option because our carbon calculation code has multiply nested procs and we would get NoMatchingProcError or MultipleMatchingProcsPerLineError:
committee :distance do quorum 'from airports' do # [...] end quorum 'from cohort' do # [...] end quorum 'default' do # [...] end endThanks to sourcify’s author, Ng Tze Yang, who added the :attached_to option when we showed him the problem. It made it possible to migrate our emission estimate web service, which comes with detailed carbon calculation methodology reports, to Ruby 1.9!
-
Zero downtime deploys on the EngineYard AppCloud
One of the ways we maximize our uptime is by tag-teaming two full production clusters:
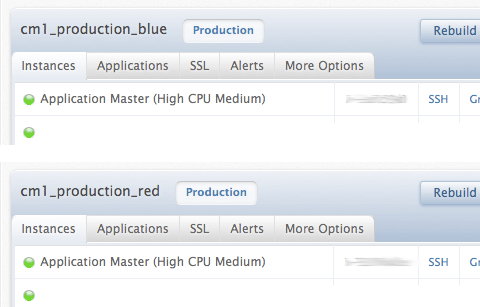
Both “red” and “blue” can support 100% of our traffic, but only one of them is in charge of carbon.brighterplanet.com at a time. That way, we can make updates to the other one, test it at full production capacity, and “tag it in” when it’s ready (by changing DNS).
This is better for us than using staging environments because we’re not holding our breath for that “final” deploy to production. The tag-team approach lets us keep the old production environment running unchanged, ready to tag back in if the deploy process goes wrong.
It’s strong rollback, in the sense that all the last-known-good instances are still running (at least until we’re totally comfortable with the new ones.) It’s also graceful, in the sense that clients are not presented with a maintenance page or scheduled outage windows.
Fact: we have to store stuff offsite
If non-replicable data lived in the database master on red or blue, then we would have to export and import it every time we tagged in or out. To solve this, we make sure that all such data is stored offsite in our reference data web service, Amazon S3, hosted Mongo, etc.
Fact: we have to wait for DNS
When we switch carbon.brighterplanet.com from red to blue, we have to wait for the DNS change to propagate. If we want to roll back, we might have to wait again. As long as the old production environment worked but just had old code, this is usually OK.
Fact: we pay for more compute hours
For a while before and after any deploy, we need both red and blue at full production capacity. That costs compute hours. We think it’s worth it to avoid a single point of failure.
Fact: we rebuild from scratch more often
When we’re not preparing for a deploy, we may take red or blue down (whichever’s not “it”) to save money. When we prepare for a deploy, therefore, we need to rebuild the instances from scratch. Since we keep our build scripts up-to-date, this has not been a problem.
-
Github Pages, Rocco, and Rake File Tasks
Recently, we spiffed up some of our emitters with enhanced documentation using Rocco, a Ruby port of Docco. We combined this with github’s ability to set up static html pages for a repo. By setting up a branch called gh-pages, Github will serve any html files in that branch. We use this feature to display Rocco-generated documentation of our carbon models (check out the flight emitter for an example).
This was great, but we were missing a way to automate the process by which Rocco will generate its documentation from the code in the master branch and place them in the gh-pages branch. Ryan Tomayko came to the rescue and wrote a rake task that creates a docs directory within the project and initializes a new git repository within the directory, which points to the project’s gh-pages branch. When documentation is generated, it is copied to the docs folder and pushed to gh-pages.
What intrigued me about the rake task was its use of file tasks. It’s a feature of rake I had never noticed before, but it’s pretty slick. A file task says, “if the specified path does not exist, execute the following code.” Since many unix tools use files for configuration, this feature plays well with many utilities, such as git, your favorite editor, etc.
For example, you could define a rake task that will create a .rvmrc for your project using your current RVM-installed ruby:
# Rakefile file '.rvmrc' do |f| File.open(f.name, 'w') do |rvmrc| rvmrc.puts "rvm #{ENV['rvm_ruby_string']}" end endWhen you run
rake .rvmrc, your .rvmrc will be generated. Try it out!There is all kinds of magic you can work with a file task. A novel way in which Ryan’s Rocco tasks use file tasks is when deciding whether to create a git remote based on whether there is a file referencing the remote in the .git configuration directory:
# Rakefile file '.git/refs/heads/gh-pages' => 'docs/' do |f| `cd docs && git branch gh-pages --track origin/gh-pages` endHappy raking!
-
Our latest tool, rapid lifecycle carbon assessment
Calculating the exact lifecycle carbon footprint of everyday goods and services is a laborious and often prohibitively expensive process. A few months ago, we set to work building a tool to help organizations get a jump start on estimating the emissions associated with the things they buy. Our goal was a flexible emissions model that could efficiently process existing data streams to calculate carbon estimates as far back through the value chain as possible for a wide spectrum of goods and services.
The result is our new purchase carbon model, released today (see the press release). It uses an advanced environmental economic input-output model to calculate a full cradle-to-consumer lifecycle carbon footprint. It works for any product or service. And it can be used automatically in a system that, for example, processes financial transaction data already present in your electronic banking records and procurement logs, giving a quick impression of the hotspots in your purchasing patterns.
To see a demo of the tool in action, check out Fedprint, a quick mashup that brings the purchase carbon model to bear on America’s largest consumer the, US federal government. Updated hourly, it spotlights the carbon footprint of the most recently awarded contracts in the Federal Purchase Data System.
For developers, the purchase model is live for experimentation and production use on Carbon Middleware. A few developer links: vehicle purchase (methodology), office supplies (in JSON), carbon model source code, API documentation
-
Open carbon code
There’s been a flurry of commentary about opening up climate model code over the past month, mostly centered around an article in Nature back in October. The discussion really broke out into the tech blogs when John Graham-Cumming opined on the reason for all the secrecy. I’m not sure I agree with his final diagnosis—that it’s just about scientists trying to not look foolish—but his call-to-action is right on:
If everyone released code then there would be (a) an improvement in code quality and (b) an ‘all boats rise’ situation as others could build on reliable code
Here’s what we’re doing at Brighter Planet:
-
We release all of our carbon models as open-source code under the AGPL.
-
We provide custom-generated methodology documentation like this for every one of our calculations.
-
We’re now using Rocco to do literate-style documentation of our methodologies (example), with specific focus on compliance with standard carbon accounting protocols.
The sad truth is that if you enter the same input data into each of the hundreds of carbon calculation software packages available now, you’re going to get a different answer each time. To be fair, all science is uncertain, so this is somewhat to be expected. But with transparency—especially documentation and open-source code—at least we’ll know why.
-
-
We are an XML web service, too
You can talk to Carbon Middleware in XML:
$ curl -v http://carbon.brighterplanet.com/automobiles.xml \ -H 'Content-Type: application/xml' \ -X POST \ --data "<make>Nissan</make>"You can receive responses in XML:
<?xml version="1.0" encoding="UTF-8"?> <hash> <emission type="float">4017.7826406033573</emission> <emission-units>kilograms</emission-units> <make> <fuel-efficiency type="float">11.7886</fuel-efficiency> <fuel-efficiency-units>kilometres_per_litre</fuel-efficiency-units> <name>Nissan</name> </make> <!-- [...] --> </hash>We’re just trying to make it easy to connect with us, whether your application speaks XML, JSON, or even x-www-form-urlencoded.
-
Back From JRubyConf
I just got back from JRubyConf in Columbus, Ohio. I had a great time meeting other Rubyists and learned a great deal about how Ruby is being integrated into enterprise environments via JRuby. It’s really exciting to see “the big guys” embracing a language and ecosystem that we at Brighter Planet enjoy using on a daily basis.
When I got back home, I decided this would be a good opportunity to try out our new meeting and lodging emissions models to come up with a carbon footprint for my trip to the conference.
I started out with the meeting space itself. I fired up Google Earth and measured the square footage of the conference center we were at - about 1,150 square meters. With the area of the space and the location, I came up with 3.08 tons of CO2e generated by the heating, cooling, and electricity usage of the space: methodology. Of course, if we considered my individual footprint, it would be 150th of that amount, given that 150 of us shared the space. This comes out to 0.02 tons.
I then looked at my hotel stay for two nights at the Hampton Inn and came up with 0.09 tons of CO2e: methodology. I looked up the lodging class from our data repository
To get to the conference, I carpooled with a couple other Rubyists from Ann Arbor, Michigan. I used 18 gallons of gas, which comes out to 68.1L. When we developed the automobile trip emitter I was surprised to learn from Seamus and Ian that the type of engine you have doesn’t make a significant difference in the amount of CO2 emitted, it really comes down to how much gasoline is burned. Therefore, our automobile trip emitter looks at the type of fuel and the quantity burned. Transportation to and from the conference came out to 0.18 tons of CO2e: methodology. Divided by the three of us, my personal transportation footprint was 0.06 tons.
Of course, no conference weekend is complete without a few good meals with fellow programmers. Over the course of the weekend, I mostly ate vegetarian, but I splurged on a trip to City Barbecue for a tasty beef brisket sandwich. I looked at all the food I ate, and calculated the share of each of the food groups I ate. My foodprint for the weekend was 0.02 tons of CO2e: methodology.
Overall, my total footprint was 0.19 tons of CO2e. Had I not carpooled, the biggest factor would have been the car trip to the venue. With carpooling, most of my emissions came from the hotel stay.
Over the past few years, there have been more and more regional Ruby conferences, and it’s great to see the community buzzing. I think it would be really cool if someone could whip up a web app that analyzes Ruby (or other) conference footprints, perhaps based on data gathered from attendees. We could make a competition out of it to see which conference has the best average per-attendee footprint!
-
Our carbon gem is now also a command-line carbon calculator
Version 0.3.0 of the
carbongem—our Ruby wrapper for the emission estimates service API—includes “command-line access” to the web service:# `carbon` carbon-> key '123ABC' => Using key 123ABC carbon-> flight => 1210.66889895298 kg CO2e flight*> origin_airport 'lax' => 1461.63846640404 kg CO2e flight*> destination_airport 'jfk' => 1733.79410872608 kg CO2e flight*> url => http://carbon.brighterplanet.com/flights.json?origin_airport=lax&destination_airport=jfk&key=123ABC flight*> done => Saved as flight #0 carbon-> exit(Notice that you’ll need a developer key to use this or any other Carbon Middleware-powered library.)
We think this feature might be especially useful to researchers and scientists who want to make “quick” calculations but still want to rely on our rigorous, transparent carbon models.
For complete documentation see the README.
Go ahead and give it a try!
$ gem install carbon $ carbon carbon-> -
Ruby 1.9.2 Marshal.dump remembers string encoding
Ruby 1.9.2 remembers encoding when it marshals a string:
ruby-1.9.2-p0 > Marshal.dump('hi') => "\x04\bI\"\ahi\x06:\x06ET" ruby-1.9.2-p0 > require 'iconv' => true ruby-1.9.2-p0 > Marshal.dump(Iconv.conv('US-ASCII', 'UTF8', 'hi')) => "\x04\bI\"\ahi\x06:\x06EF"Ruby 1.8 did not:
ruby-1.8.7-head > Marshal.dump('hi') => "\004\b\"\ahi" ruby-1.8.7-head > require 'iconv' => true ruby-1.8.7-head > Marshal.dump(Iconv.conv('US-ASCII', 'UTF8', 'hi')) => "\004\b\"\ahi" -
Calculating hotel emissions
Following up on our recent release of an event module for our carbon middleware service, we’re excited to announce the release of a lodging module.
Developers can now use our API to calculate emissions from hotel energy use within their own applications. The calculations use data from the EIA’s Commercial Buildings Energy Consumption Survey and the EPA’s eGRID, which are automatically imported to our database and updated nightly to ensure currency.
Possible applications of the lodging emitter include a company calculating Scope 3 emissions from business travel, a hotel booking website calculating your stay’s emissions, a travel agent adding offsets for lodging emissions to a vacation package… but don’t let us limit your thinking!
We’re hard at work cranking out more emitters, so stay tuned for updates.
-
Event carbon calculation added to middleware toolkit
For years we’ve been doing custom carbon emissions inventories for meetings and events ranging from conventions and conferences to music festivals and sporting events. Now we’ve released a new meetings module of our carbon middleware service that lets software developers build event carbon calculation into their own applications.
The meetings and events emitter, accessed through our API, lets users specify a range of characteristics to calculate emissions from venue energy use. Used in combination with other carbon middleware emitters like transport, hotel stays, food, and fuel purchases, an event inventory can be expanded to cover the desired emissions scope.
Underpinning this event carbon model are authoritative data from the EIA’s Commercial Buildings Energy Consumption Survey and the EPA’s eGRID, imported automatically to our system on a daily basis to ensure currency.
We’re excited to see website and software developers put the tools to use. We’ve got applications in mind ranging from widgets that let wedding and party planners estimate their impact, to platforms that enable corporations to manage all aspects of convention and summit carbon footprints. But IT engineers will no doubt surprise us with innovative ways to integrate this carbon data into their systems.
Events and meetings can be great opportunities not only to meet your organizations’ own sustainability goals, but also to promote conservation by helping to enlist participants and attendees in the emissions calculation and reduction process. In working with event organizers we’ve had great success using a four-pronged approach that addresses event carbon inventorying, emissions reduction initiatives, mitigation through offsetting, and attendee participation in measuring, reducing, and offsetting their own event travel emissions.
-
Expanding lifecycle analysis capabilities with EIO-LCA data
We’re pleased to announce that we’ve just added the Economic Input-Output Life Cycle Assessment (EIO-LCA) model to our carbon data resources. Licensing this authoritative model further expands our ability to perform lifecycle and supply chain carbon emissions analysis.
The carbon accounting field is increasingly focusing on Scope 3 emissions, including supply chain and product lifecyle emissions. Supplier sustainability programs by institutions like Walmart, IBM, P&G, and the federal government are driven by the realization that for many organizations, embodied emissions represent the majority of total carbon impact.
The EIO-LCA model from Carnegie Melon University’s Green Design Institute combines federal Economic Census data with research on the environmental impacts of hundreds of economic sectors. It enables lifecycle assessment for all phases of production including raw materials extraction, transport, manufacturing, and retail.
Through our new partnership with CMU, Brighter Planet will provide rapid environmental impact analysis for goods and services such as electronics, food, healthcare, vehicles, consulting, entertainment, clothing, and supplies.
-
Use Amazon SQS to get emission estimates
You can get emission estimates by queueing up messages on Amazon SQS:
$ curl -v https://queue.amazonaws.com/121562143717/cm1_production_incoming -X POST --data "Action=SendMessage&Version=2009-02-01&MessageBody=emitter%3Dautomobile%26make%3DNissan%26guid%3DMyFavoriteCar%26key%3D86f7e437faa5a7fce15d1ddcb9eaeaea377667b8" * About to connect() to queue.amazonaws.com port 443 (#0) * Trying 72.21.211.87... connected * Connected to queue.amazonaws.com (72.21.211.87) port 443 (#0) # eliding some standard server messages for brevity . . . > POST /121562143717/cm1_production_incoming HTTP/1.1 > User-Agent: curl/7.20.0 (i386-apple-darwin9.8.0) libcurl/7.20.0 OpenSSL/0.9.8m zlib/1.2.3 libidn/1.16 > Host: queue.amazonaws.com > Accept: */* > Content-Length: 158 > Content-Type: application/x-www-form-urlencoded > < HTTP/1.1 200 OK < Content-Type: text/xml < Transfer-Encoding: chunked < Date: Wed, 11 Aug 2010 08:20:56 GMT < Server: AWS Simple Queue Service < <?xml version="1.0"?> * Connection #0 to host queue.amazonaws.com left intact * Closing connection #0 * SSLv3, TLS alert, Client hello (1): <SendMessageResponse xmlns="http://queue.amazonaws.com/doc/2009-02-01/"><SendMessageResult><MD5OfMessageBody>fb29551a9e1c36dcf1b8ba624695210a</MD5OfMessageBody><MessageId>5d48a63b-5416-4d35-8bc5-65ace74f4d42</MessageId></SendMessageResult><ResponseMetadata><RequestId>a3e0d71a-9e47-493b-a92c-29b37393e899</RequestId></ResponseMetadata></SendMessageResponse>You need to use this SQS queue: (but you don’t need an SQS account, it’s just a standard HTTP POST)
https://queue.amazonaws.com/121562143717/cm1_production_incomingAs you can see, the MessageBody is the url-encoded form of a querystring:
emitter=automobile&make=Nissan&guid=MyFavoriteCar&key=86f7e437faa5a7fce15d1ddcb9eaeaea377667b8Wait a minute, isn’t that an empty response body?
Correct. This is an asynchronous way of doing things. The result in JSON format will appear as soon as it is calculated (usually in a few seconds).
If you need an answer in realtime, then you should skip SQS and hit mostly the same querystring.
Why use SQS?
Depending on your environment, you may already have an excellent SQS client library. You’ll have the high availability of Amazon web services combined with competitive Brighter Planet pricing for asynchronous (rather than realtime) emission estimates.
Depending on your application, set-it-and-forget-it may be a natural fit. We’ll store the result for you in JSON format at an effectively randomized URL, which is perfect for AJAX calls that display results in a browser. In general, if you can queue up the emission estimate now and count on a JSON-enabled client to pull the results later, this is a good way to go.
How did you calculate the result URL?
Just SHA1 the string key plus guid. No salt or separators or anything, just 86f7e437faa5a7fce15d1ddcb9eaeaea377667b8MyFavoriteCar in this case.
ruby-1.8.7-head > require 'digest/sha1' => true ruby-1.8.7-head > Digest::SHA1.hexdigest('86f7e437faa5a7fce15d1ddcb9eaeaea377667b8MyFavoriteCar') => "745c4bcda8234186178e8430ae55f38913a5f042"Other notes
- We host the storage on Amazon S3, so you’ll benefit from high-availability there too.
- If you’re using Ruby, you can use our carbon gem with the :guid option.
- If you would rather have us POST the result back to your waiting servers, you can pass &callback=http%3A%2F%2Fmyserver.example.com%2Fcallback-receiver.php.
-
Sharing Rails views with Jekyll
In my last post I discussed how we share a single layout between Rails apps. This has been a lifesaver for us as we manage a half-dozen production apps. But a couple of our sites—our developer hub and this here blog—don’t use Rails. They’re both Jekyll sites running on GitHub Pages.
Obviously we can’t rely on the Rails Engine features in our shared layout gem to load the layout into the right places. What are we to do?
One step at a time
Luckily Jekyll already includes the basic building blocks of our solution: layouts and includes. Layouts, described here are Liquid templates, and Jekyll ships with a custom Liquid extension that enables includes.
All we need to do then is transform our Rails layout into a Jekyll layout and use includes instead of partials. Ready, set, go.
When in Rome
Jekyll is a static site generator. Following this lead, our transformations will be manually executed and staticly stored within your Jekyll site. The easiest way to get started is to set up a task in your Rakefile:
require 'net/http' require 'uri' require 'erb' require 'lib/stubs' namespace :layout do task :build do File.open File.join(File.dirname(__FILE__), '_layouts', 'default.html'), 'w' do |f| f.puts ERB.new(Net::HTTP.get(URI.parse('http://github.com/brighterplanet/brighter_planet_layout/raw/master/app/views/layouts/brighter_planet.html.erb'))).result(Layout.new.get_binding { |*pages| '{ { content } }' if pages.empty? }) end end endWhat’s going on here? Rake is fetching the raw ERB of your layout from the gem’s repository, sending it to ERB for processing, and then storing the result as your Jekyll site’s
defaultlayout.I should call your attention to a couple of tricky bits here.
Bindings
First, this business about bindings. ERB needs a “binding” to work–that is, a context within which it can access instance methods, variables, etc. Rails takes care of this for you, but since we’re invoking ERB here directly, we have to tell it where to bind. Why is this important? Your layout probably uses methods like
stylesheet_link_tagorrenderto get its job done. If we don’t provide those methods in ERB’s context, we’ll getNoMethodErrorall over the place. The easiest way to fool ERB is with a fake context, which we’ll put inlib/stubs.rb:class Layout def stylesheet_link_tag(*sheets) sheets.collect do |sheet| "<link rel=\"stylesheet\" type=\"text/css\" href=\"/stylesheets/#{sheet}.css\" />" end end def javascript_include_tag(*args); end def render(options = {}) "{٪ include #{options[:partial][/[a-z_]*$/]}.html ٪}" end def get_binding binding end endYou can see how we re-interpret these method calls in a way that’s meaningful to Jekyll. (Note that since
bindingis a private method we have to publicize it with theget_bindingwrapper.)Yields
The second tricky bit is dealing with your standard Rails layout’s multiple
yieldcalls, the consequence of usingcontent_forblocks in your views. We have to anticipate this and set up ERB to act accordingly. Where do we even capture arguments to yield? Turns out the correct place to do this onget_binding, our wrapper to the privatebindingmethod. Now theyieldwe’re interested in—the one where we want Jekyll content to go—is the one called without any arguments. So we set the block to output thecontentLiquid tag when it seesyieldcalled with an empty argument set. Otheryieldcalls—to dumpcontent_formaterial, which could never be prepared by Jekyll anyways—are simply ignored.And we’re done
Your complete layout package will probably include several partials—each with its own fake context class in
stubs.rb—as well as asset files. To build your layout from its source in the cloud, just$ rake layout:buildCheck out our developer hub’s
Rakefileandstubs.rbfor all the details. -
Bundler to the Max
I have been spending the past few weeks creating and refactoring our carbon model gems, with the goal of making them easy to enhance, fix, and test by climate scientists and Ruby developers. I wanted to make contributing a simple process and bundler fit the bill quite well.
A not-so-widely-known feature of the Rubygems API is the ability to declare a gem’s development dependencies, along with its runtime dependencies. If one planned on making changes to one of the emitter gems and testing it, she could run
gem install <emitter_gem> --developmentand have any needed testing gems installed for the emitter gem.This is all fine and good, but I chose to use bundler to manage our dependencies, as it adds a few extras that have been a tremendous help to us. To contribute to any of our gems, a developer can follow a simple process:
$ git clone git://github.com/brighterplanet/<gem>.git $ cd <gem> $ gem install bundler --pre # this is needed until bundler 1.0 is released $ bundle install $ rakeAnd Bob’s your uncle!
Bundler + Gemspecs
The first goodie that bundler provides is the ability to use the gem’s own gemspec to define the dependencies needed for development. For instance, our flight gem has a gemspec with dependencies:
Gem::Specification.new do |s| # ... s.add_development_dependency(%q<activerecord>, ["= 3.0.0.beta4"]) s.add_development_dependency(%q<bundler>, [">= 1.0.0.beta.2"]) s.add_development_dependency(%q<cucumber>, ["= 0.8.3"]) s.add_development_dependency(%q<jeweler>, ["= 1.4.0"]) s.add_development_dependency(%q<rake>, [">= 0"]) s.add_development_dependency(%q<rdoc>, [">= 0"]) s.add_development_dependency(%q<rspec>, ["= 2.0.0.beta.17"]) s.add_development_dependency(%q<sniff>, ["= 0.0.10"]) s.add_runtime_dependency(%q<characterizable>, ["= 0.0.12"]) s.add_runtime_dependency(%q<data_miner>, ["= 0.5.2"]) s.add_runtime_dependency(%q<earth>, ["= 0.0.7"]) s.add_runtime_dependency(%q<falls_back_on>, ["= 0.0.2"]) s.add_runtime_dependency(%q<fast_timestamp>, ["= 0.0.4"]) s.add_runtime_dependency(%q<leap>, ["= 0.4.1"]) s.add_runtime_dependency(%q<summary_judgement>, ["= 1.3.8"]) s.add_runtime_dependency(%q<timeframe>, ["= 0.0.8"]) s.add_runtime_dependency(%q<weighted_average>, ["= 0.0.4"]) # ... endInstead of defining these dependencies in both flight.gemspec and in Gemfile, we can instead give the following directive in our Gemfile:
gemspec :path => '.'Bundler + Paths
We have a chain of gem dependencies, where an emitter gem depends on the sniff gem for development, which in turn depends on the earth gem for data models. In the olden days (like, 4 months ago) if I made a change to sniff, I would have to rebuild the gem and reinstall it. With bundler, I can simply tell my emitter gem to use a path to my local sniff repo as the gem source:
gem 'sniff', :path => '../sniff'Now, any changes I make to sniff instantly appear in the emitter gem!
I had to add some special logic (a hack, if you will) to my gemspec definition for this to work, because the above gem statement in my Gemfile would conflict with the dependency listed in my gemspec (remember, I’m using my gemspec to tell bundler what gems I need). To get around this, I added an if clause to my gemspec definition that checks for an environment variable. If this variable exists, the gemspec will not request the gem and bundler will instead use my custom gem requirement that uses a local path:
# Rakefile (we use jeweler to generate our gemspecs) Jeweler::Tasks.new do |gem| # ... gem.add_development_dependency 'sniff', '=0.0.10' unless ENV['LOCAL_SNIFF'] # ... end# Gemfile gem 'sniff', :path => ENV['LOCAL_SNIFF'] if ENV['LOCAL_SNIFF']So now, if I want to make some changes to the sniff gem and test them out in my emitter, I do:
$ cd sniff # work work work $ cd ../[emitter] $ export LOCAL_SNIFF=~/sniff $ rake gemspec $ bundle update # ... sniff (0.0.13) using path /Users/dkastner/sniff # ...And then Bob is my uncle.
Bundler + Rakefile
This next idea has some drawbacks in terms of code cleanliness, but I think it offers a good way to point contributers in the right direction. One thing that frustrated me about Jeweler was that if I wanted to contribute to a gem, my typical work flow went like:
$ cd [project] # work work work $ rake test LoadError: No such file: 'jeweler' $ gem install jeweler $ rake test LoadError: No such file: 'shoulda' # etc etcI attempted to simplify this process, so a new developer who doesn’t read the README should be able to just do:
$ cd [emitter] # work work work $ rake test You need to `gem install bundler` and then run `bundle install` to run rake tasks $ gem install bundler $ bundle install $ rake test All tests pass!I achieved this by adding the following code to the top of the Rakefile:
require 'rubygems' begin require 'bundler' Bundler.setup rescue LoadError puts 'You must `gem install bundler` and `bundle install` to run rake tasks' endThis was convenient, but it created a chicken and egg problem: in order to generate a gemspec for the first time, bundler needed to know which dependencies it needed, which meant that it needed the gemspec, which is generated by the Rakefile, which requires bundler, which requires the gemspec, etc. etc. I overcame this problem by allowing an override:
require 'rubygems' unless ENV['NOBUNDLE'] begin require 'bundler' Bundler.setup rescue LoadError puts 'You must `gem install bundler` and `bundle install` to run rake tasks' end endSo, if you’re really desparate, you can run
rake test NOBUNDLE=trueMore on Local Gems
Now that I had a way to easily tell bundler to use an actual gem or a local repo holding the gem, I wanted a way to quickly “flip the switch.” I wrote up a quick function in my ~/.bash_profile:
function mod_devgem() { var="LOCAL_`echo $2 | tr 'a-z' 'A-Z'`" if [ "$1" == "disable" ] then echo "unset $var" unset $var else dir=${3:-"~/$2"} echo "export $var=$dir" export $var=$dir fi } function devgems () { # Usage: devgems [enable|disable] [gemname] cmd=${1:-"enable"} if [ "$1" == "list" ] then env | grep LOCAL return fi if [ -z $2 ] then mod_devgem $cmd characterizable mod_devgem $cmd cohort_scope mod_devgem $cmd falls_back_on mod_devgem $cmd leap mod_devgem $cmd loose_tight_dictionary mod_devgem $cmd sniff mod_devgem $cmd data_miner mod_devgem $cmd earth else mod_devgem $cmd $2 fi }This gives me a few commands:
$ devgems enable sniff # sets LOCAL_SNIFF=~/sniff $ devgems disable sniff # clears LOCAL_SNIFF $ devgems list # lists each LOCAL_ environment variableI now have a well-oiled gem development machine!
Overall, after a few frustrations with bundler, I’m now quite happy with it, especially the power and convenience it gives me in developing gems.
I’m really interested to hear any of your thoughts on this. Drop me a line at @dkastner.
-
Sharing views across Rails 3 apps
Here at Brighter Planet we run several production Rails 3 apps, including the emission estimates service, the climate data service, and our keyserver. As the person reponsible for much of our recent front-end work, I wasn’t really looking forward to maintaining a half-dozen different versions of what is mostly the same layout. I wanted to DRY the situation up. What I really wanted was to put all the shared stuff into a gem that I could require from all of our apps that would just sort of insinuate itself into all the right places.
Luckily Rails 3 makes this possible, after a fashion. The key trick is giving your plugin a Railtie, which isn’t documented very well yet–this gist from Jose Valim is the best I could find.
To get started just add a file in
lib/gemname/calledrailtie.rband require it from the maingemname.rbfile:module BrighterPlanetLayout class Railtie < Rails::Railtie end endBecause it inherits from Rails::Railtie, you don’t have to “declare” the Railtie–Rails automatically keeps track of it and calls the right parts when they’re needed.
The easy part is telling Rails to add your gem’s view path to the app’s view path:
module BrighterPlanetLayout class Railtie < Rails::Railtie initializer 'brighter_planet_layout.add_paths' do |app| app.paths.app.views.push BrighterPlanetLayout.view_path end end endTelling ApplicationController to use the layout in your gem’s view path as the default is a little tricker–you have to use a
to_prepareblock:module BrighterPlanetLayout class Railtie < Rails::Railtie # ... config.to_prepare do ApplicationController.layout 'brighter_planet' end end endIt turns out the hardest part is hooking Rails up to your gem’s static asset files–stylesheets, images, fonts, etc. For that we add another instance of
ActionDispatch::Staticto the Rack middleware stack:module BrighterPlanetLayout class Railtie < Rails::Railtie config.app_middleware.use '::ActionDispatch::Static', BrighterPlanetLayout.public_path # ... end endThis is a fine solution in the development environment, but it’s too slow for production–your webserver has to fire up Rails just to push an image binary, for example. So in production we just copy static files to the app’s
publicdir:module BrighterPlanetLayout class Railtie < Rails::Railtie if BrighterPlanetLayout.serve_static_files_using_rack? # "if in development environment" config.app_middleware.use '::ActionDispatch::Static', BrighterPlanetLayout.public_path end initializer 'brighter_planet_layout.copy_static_files_to_web_server_document_root' do if BrighterPlanetLayout.copy_static_files? # "if in production" BrighterPlanetLayout.copy_static_files_to_web_server_document_root end end # ... end endAnd that’s it. Check out the gem source for details on the folder structure and for additional tricks like loading shared helpers. Next time: how to use this shared layout with Jekyll.
-
Real code examples in our integration guide
I realize that not everybody uses Ruby/Rails, so integration with our emission estimate web service won’t always be facilitated by our sharp little carbon gem.
Still, if I were a third-party developer, there is nothing I would want more than unfiltered code examples from a real integration, no matter the language.
Therefore I present our unfinished integration guide, complete with real diffs.
-
Relaunching the blog
We’ve been hosting our own blog for a couple of years now on a custom Wordpress installation, dealing from time to time with all the idiosyncracies of a PHP application. As part of the process of launching our developer ecosystem, we thought we’d take the opportunity to transition to a more convenient, reliable approach.
After looking at a gazillion options (seriously, where are the blogging platforms that support syntax highlighting out of the box?), we settled on jekyll, which we’re already using for our Developer Hub. We’re hosting this using GitHub Pages, so deploys are as simple as
$ git pushAnyways, expect to see a greater focus on the technology behind Brighter Planet here on the new blog. Here we go!
-
Empowering 350.orgâs Climate Action Fund

In the latest chapter of our perennial partnership with 350.org, Brighter Planet will provide the technology and underwriting to make 350’s crowdsourced Project Funds for Climate Action a reality.
Last fall, 350.org organized what CNN called “the most widespread day of political action in the planet’s history,” inspiring more than 5,000 events in 181 countries as part of the International Day of Climate Action. They continue to push the issue of climate change to forefront, inspiring a much needed sense of urgency in the fight to prevent catastrophic global change. Their slogan for this year, “Get to Work,” encourages grassroots action around the world, challenging people to step up and be the drivers of change in their communities, forcing our leaders to take action. In conjunction with 1010global.org, which has already signed close to 80,000 people since January in demanding a 10% annual reduction in carbon emissions, 350.org has put forth 10/10/10 as a global day of action.
Beginning today and leading up to the 10/10/10 Work Parties, 350.org will give out eight $1000 microgrants every month through their 350 Project Funds for Climate Action, funding Work Party projects that raise awareness about climate change, promote renewable energy, and show clearly that progress is possible.
Like Brighter Planet’s Project Fund, the 350 Project Funds for Climate Action will powered by our new wowcrowd platform, and the contest structure will be similar. Anybody can submit project proposals, anybody can vote on their favorite ideas, and each month the project with the most votes will be awarded a grant. Project ideas range from organized tree plantings to retrofitting buildings with more efficient CFL’s to setting up bike repair workshops.
As part of our partnership with 350.org, we’ve donated this month’s Project Fund grant money to the 350 Project Climate Action Fund. You can do your part as well—we encourage you to cast your ballots to help determine the winners, and to submit your climate project ideas to the fund. And as 10/10/10 approaches, you can also participate in helping make 350 ppm a reality by joining a local Work Party or registering your own. With your help, thousands of communities will come together to make 10/10 the biggest day of practical action to cut carbon the world has ever seen.
–the Brighter Planet team
-
Case Foundation's Wowcrowd interview
Last week, our friends at The Case Foundation sat down with Brighter Planet’s Robbie Adler to talk about the release of our new crowdsourcing technology platform Wowcrowd:
Josh: Thanks again for speaking to us today Robbie. Just to clarify for all of those who might be a bit confused, what exactly is Wowcrowd?
Robbie: Wowcrowd is a social web application that gives organizations the tools to crowdsource the allocation of funds, which helps them engage their stakeholders and surface bright ideas.
The concept is simple. An organization with a Wowcrowd account earmarks a pool of money for a particular mission, and then opens the process to their users—their employees, members, customers, constituents, or the general public. Individual users submit proposed ideas for how the funding could be spent, and then all the users vote to decide which of the proposals will get funded and be realized.
Josh: What are the benefits of challenges and contests like the ones being run on Wowcrowd?
Robbie: A well-run crowdsourced program can provide some very important benefits for an organization. It opens a slice of the decision-making process to their stakeholders, which engages them as active participants in the organization’s mission rather than as passive donors or members—and an engaged constituent base clearly offers many advantages.
It can also be a strong PR tool, because as we’ve learned, contest participants (including proposal submitters and voters) end up devoting their own energy and effort to spreading the word in support of their cause, effectively creating brand ambassadors for the organization. Administered through an online tool like Wowcrowd, these programs can be easily integrated with other social media channels to efficiently promote the fund and the organization.
Of course, another big benefit is the crowdsourced ideas themselves. By tapping into the collective intelligence of their stakeholders, a contest administrator can efficiently surface creative ideas that are diverse and compelling—ideas they likely wouldn’t have thought of themselves.
You’ll find the full interview, conducted by Joshua Tabb, on the Case Foundation blog.
Established in 1997 by Jean and Steve Case, the Case Foundation utilizes a citizen-centered approach to encourage civic engagement in the U.S. and around the Globe. The organization focuses on the “big-swing-for-the-fences ideas” with large potential for change to achieve their mission: “invest in people and ideas that can change the world.” Recently they conducted the America’s Giving Challenge, a one month competition to unite people around the issues they care about, increase awareness for the issues, and attract donors. The challenge was enormously successful, bringing in over 105,000 donations and raising $2.1 million for various nonprofit causes.
-
Emissions modeling methodology published

The field of carbon emissions modeling is in a period of rapid evolution, shaped by ongoing transformations in climate science, information technology, government regulation, and the business environment. Demand for data about the impacts of carbon-emitting activities is steadily increasing— but so too are the complexity, opacity, and inconsistency of emissions calculation methodologies, undermining advancements in the field.
At a time when carbon intelligence has an urgent role to play in stemming catastrophic climate change, a more deliberate approach to carbon modeling is warranted. Reactive attempts by authorities to establish consistent, transparent methodology standards have been only marginally successful, more so in the sphere of corporate carbon footprinting than elsewhere. As a small company developing carbon emissions models, Brighter Planet is committed to doing our part in helping transform this field.
In developing our modeling approach, we were guided by three core principles: rigor, flexibility, and transparency. We knew that our system would need to provide high quality estimates that accounted for an emitter’s full and complete climate impact. We knew that the model would need to operate given huge real-world variability in the quantity and quality of data available about emissions sources. And we knew that radical openness and collaboration would be critical to maintaining trust and quality in a rapidly evolving space at the intersection of multiple fields.
Our goal for this methodology paper was to provide insight into the approach and data that we use to model greenhouse gas emissions, both to help fulfill our commitment to openness by documenting our own practices, and to foster a discussion about best practices in carbon modeling to help advance the field. We welcome discussion and collaboration on this project!
–The Brighter Planet Team
-
Imperfect Planning and the Best Keys
 I recently received some requests from BlenderNation to write a little about how to animate a bumblebee. Toward this goal I can’t help but think about the unpredictability of planning a project under deadline and the importance of keyframing by hand.
I recently received some requests from BlenderNation to write a little about how to animate a bumblebee. Toward this goal I can’t help but think about the unpredictability of planning a project under deadline and the importance of keyframing by hand.First, the planning. I could lie and talk about what an ideal planner I am. I could draw up fake storyboards and draft a fake script to make it look as though I intended every choice of this project from the start as though some twist of genius granted me direct connection to a god-like inspiration. But it doesn’t work that way, not on any project that I’ve known.
Given this, one might surmise that my idea of planning is to shoot from the hip and hope for the best. But that isn’t it either. That suggests that planning is irrelevant; that good work can come from reckless behavior. Maybe it can to some people, but not to me, and never under deadline.
The projects I have taken the time to plan have all succeeded to some degree or another. The projects I have failed to plan have failed themselves. But for the ones that worked, there was always a plan.
Paradoxically, the plan, however good, has always changed at some point between the beginning of production and the end. For example this bumblebee project began without a single bumblebee. It was supposed to be about flowers. I happily started the script, imagining how the beautiful sun would shine its nourishing light on various plants until their seeds fell down to the soil to grow into a garden.
Then I set to work on a concise voice-over narration script with lots of puns and active verbs. I sketched out a couple storyboard drawings of the plants, their seeds swelling and dropping. Everything was going according to plan. But as I opened up Blender to begin modeling something inside of me groaned.
The work was boring. I had seven shots of seven plants relishing in the sunlight and growing their seeds. After modeling just one I was sick already of the plants and the sunshine and the glory of nature. My heart sank and I began to look for ways to jettison the entire project without causing too much collateral damage.
This is when the bee flew in to land on the back of my pollen clogged brain, and when he did everything about the plan changed. Now there was a protagonist, the glimmer of a story, and an idea worth planning for.
But before charging through the steps that carry any animation project from beginning to end – write, storyboard, model, rig, animate, etc. – I counted the days I had remaining: Ten days till deadline. With that number in my head I planned a film that I could produce in five. In the end it took me twelve. <p style="text-align: center;">
 </p>
</p>Now keyframing. For those unfamiliar with the animation term, each keyframe is an image that the animator creates to bring meaning to a film. Every keyframe in a finished film is necessary. Like the keystone in an arch, if a single keyframe goes missing the whole piece can collapse.
In 3D computer animation keyframes are an opportunity for human touch. Keyframes take time to build for they must be made one by one by hand. The amount of labor it takes to keyframe an animation has turned away many interested people from the field. It’s just too much work. In the days of classical hand-drawn animation this labor seemed well understood. However, 3D computer animation suffers a myth that animation with the help of a enough computers can be easy. If we could only build the perfect rig, or hire enough helpers or program the perfect animation software then animation could be effortless.
But if that day ever comes when all one must do is push the animate button and pull the emotion lever to somewhere between happy and sad, then animation will be finished, no longer interesting.
Take the challenge away from the animators and the viewers will find no joy in watching what they make. For me it is awe that I experience when I witness animation far greater than my own. It drives me to improve and allows me to appreciate how far I’ve come. I am not a great animator by any means, but I know now that animation is worth the effort.
3D computer animation is a powerful, sophisticated, precise tool. But it is only a tool. It is not the art. It is not the artist. My older brother Michael said to me recently, “I’ve given up on the ability of computers to solve the problems of the world.” He went on to suggest that a computer is like a bulldozer. A bulldozer is very good at pushing dirt around. Bulldozers have come a long way since their ancestor, the rake. A modern bulldozer is capable of pushing so much dirt around so quickly it boggles the mind. But a bulldozer is only beautiful so long as all you need is dirt. Anything more requires a human being.
This is the keyframe, that thing that only a single human being can do, that moment of communication between author and audience, the image that makes all your effort into more that a hill of dirt.
So please, pour all of your energy into those keyframes, all of it. Your keyframes decide the success of the piece; the rest will follow.
In the movie Gattaca, two brothers race by swimming straight out to sea. The loser is whoever turns back first. Always the same brother loses, the one not biologically designed for super-human strength. Over and over growing up they race until one day the weaker brother wins. The stronger cannot fathom how. “This is how I did it, Anton: I never saved anything for the swim back.”
If you have never worked on an animation yourself then to stumble upon someone else’s work-in-progress can be baffling. The computer monitor becomes a portal into some strange three-dimensional world constantly orbiting a pale gray character wrapped in wire. The unfinished character stares vacantly forward, its arms out stiffly to the sides as though recently crucified. Even more baffling to the onlooker is how the animator, back hunched, fingers clicking rapidly at the keyboard and mouse, seems not to mind the gruesome monster and even thinks it handsome.
It is a work in progress. It does not yet communicate anything to the outside world, but it will. All that is missing are the keyframes. Those are the life of the piece. Once they are in place the arch stands up without support. The bridge is built. Communication flows. <p style="text-align: center;">
 </p>
</p>So that’s how you animate a bee! I would imagine that solving climate change has an equally logical answer. If you discover what this answer is, please let me know. In the meantime I’ll be working at it myself, hoping another bee lands on my brain.
-Daniel
-
Behind the Scenes of the Project Fund Video
Check out our latest video made with the wonderful Blender animation software.
Download the behind the scenes files!
This project began with a script about plants, which turned into a storyboard of pencil sketches, plants, flowers, seeds of all kinds swelling and dropping from their branches. These sketches evolved into a collection of 3d models, and rigs and everything seemed to be going according to plan.
Then a bee flew into the room and landed near my desk. It’s wings slowed from a blur to rest on its back. When the little guy looked up at me everything changed. I threw out the script and the storyboard. I shut down my animation software and started over with pencil and paper to tell the story of the bee.
Voting for this month’s projects began yesterday and closes on the 15th, so vote today!
-
Behind the Scenes of âYour Planet, Brighterâ
If you’d like to explore more about how this movie was made, download the project file and explore it with Blender’s magnificent animation software.
-
Tame your carbon footprint with the new brighterplanet.com
We turned on our new website for real this week. w00t! WAHOO!! YEE-HAWW!!! (Beg pardon — that little celebration has been more than a year in coming.)
The new brighterplanet.com is a free, fun, and easy-to-use web utility that will help you succeed in living a more planet-friendly lifestyle, in the same way that other online tools help people get a handle on their finances or adopt a diet/fitness regimen. All you need to get rolling is a desire to be part of the solution to environmental challenges. We’ll show you — and help you show others — how personal choices add up, how to get started, and where to pick off low-hanging fruit.
Feedback from early-bird users was immensely helpful in refining the app through our beta period. And (now that we’ve danced our little jig, kinda like these guys), it’s back to work. We’ll continue to shape brighterplanet.com based on your feedback, and we’re not planning to rest for a long while. There’s lots to do:
- Twitter integration. Soon you'll be able to link your twitter account to your Brighter Planet profile. This will give you easy access to sharing your experience with your friends.
- Facebook integration. Facebook connect is coming soon. You'll be able to interact with your facebook friends right from the Brighter Planet website.
- Widgets and badges that can be embedded virtually anywhere.
- Share your Brighter Planet activity anywhere via a custom RSS feed.
- Carbon profiler precision: soon you'll be able to tell us how much waste you generate, and how much of it is recycled. You'll also be able to calculate your pet's emissions!
- Carbon profiler UX enhancements: we're constantly working on new ways to make entering information easier.
- Compare your footprint to others on Brighter Planet.
- More third-party integration. We're all set to start doing data handshakes with some of the big get-things-done services (spots where you pay your bills, do some shopping, make travel plans, etc).
- Historical data / visualizations. Set conservation goals and track your progress over time.
What’s missing from this list? What new feature (or change to an existing one) would make you the most excited?
Leave your thoughts here, or on our GetSatisfaction.com support site. Talk to us on Twitter, or Facebook. Wait… What?! You’re not signed up yet?!! Good grief, there’s no time for delay — get thee to the registration page!!
-
Behind the Scenes of Big Feet, Little Planet
There has been some interest in how the video Big Feet, Little Planet was made. Here is a breakdown of the workflow.
Big Feet, Little Planet from Brighter Planet on Vimeo.
I was trying to visualize the idea of people stepping onto a scale and finding out the weight of their carbon footprint, so I spent a couple of hours designing a sheet of glass that I could film from beneath which would safely support a full grown human standing on top.
There were a couple of problems with this approach. It required more money to build a safe and sturdy structure than I was willing to spend. And it would result in a shot looking straight up into someone’s crotch.
Thankfully my colleague Mike had the genius idea of turning the equation on its side. “Why not have people lay down on the floor and put their feet up against a window?” he suggested. This solved the safety issue and the crotch issue, so I grabbed an old storm window from my basement and we were off.
We filmed in three environments: an abstract/hi-tech space, an office space, and a home/outdoor space. The first two feet were mens’ feet, the final one was a woman’s. I’m not sure if you can tell a person’s sex just by looking at their feet, but you can definitely tell how hairy a person’s legs are and I wanted at least one nice smooth leg.
All three shots were filmed on location, so we set up the storm window, set up the lights or the bounce cards and got a couple takes. It was surprisingly difficult for the models to hit their mark on the glass quickly and accurately. They could hit the mark if they went slowly, but it was often too slow to work for the shot. However once their foot was already on the glass they could pull it down out of frame no problem. So I ended up reversing the footage on two of the shots. In the finished piece it looks like they’re putting their foot up, in real life they are taking it down.
With the shots in place I opened up Blender, a fantastic and free animation suite and modeled the effects.
If you are curious to look deeper into the process, here are the production files.
If you’ve never used Blender feel free to download it. You’ll need it in order to explore the files above.
Once you’ve got Blender installed, just double click on a file to open it. Then tap your left or right arrow keys to step through the animation frame by frame.
-Daniel
-
Why Iâm psyched about Brighter Planetâs web app (part 1)
My name’s Ian Wilker; I’ve been on the Brighter Planet bandwagon for a couple months now, serving as your friendly neighborhood community manager. (Or “community advocate,” ”unmarketer,” ”pinko marketer,” Love Boat–style “social director” … I’m here to help Brighter Planet listen to, talk with, and in the end be responsive to our online user community.
I could have offered up a “Hello world” post here some time ago, but I’m kind of glad I waited – we’ve released the beta version of our new web service, and I’m rarin’ to get out into worlds online and off to talk about it and get a good feedback loop rolling. Now I can get into the nitty-gritty, into the reasons the prospect of joining Brighter Planet made me feel all tingly.
I grew up in rural Vermont, and my parents got me and brother Josh out into the woods at every opportunity, through all seasons. It wasn’t until much later, as a city-dwelling young adult, that I realized what a gift I’d been given by all that camping, backpacking, fishing, skiing, and so on. I started getting back out into the mountains at every opportunity; there’s just no place I feel more alive than in the woods, soaking in the infinitely rich sights, smells, sounds, textures of the natural world.
Over time, through stints as a book editor and then as a web nerd, I gravitated toward jobs that brought my abiding interest in the natural world into the work. I’ve done online-communications work for a large environmental organization for going on nine years. And again and again over that time, I’ve puzzled over the problem of how to show more people that doing the right thing by the environment is rarely hard – it’s just different from what most of us are used to. It’s about examining a lot of habitual behavior, and tweaking those behaviors when there’s a more planet-friendly way to get something done.
And anyone can learn new habits – IF one goes about it in the right way. It’s process and practice that we get tangled up in. At least that’s how I’m built, it seems: give me a cut-and-dried blueprint of exactly what I want to do a little differently in a given situation, and I’m a lot more likely to start making the change. Give me a way to track the fruits of choosing a new option at a given decision point – or to see, plain as day, the stagnancy of not doing that new option, and I’ll be much more likely to really commit to the change.
We’re still building it out, but this is exactly what this next-generation of Brighter Planet will give me:
- What to do next time I’m (buying some fruit; taking a shower; running the dishwasher – on and on, ad infinitum)
- What making that more-sustainable choice actually does to my overall footprint – e.g. immediate feedback on the consequences of a given behavior.
Ain’t that cool? And even better: That’s just for starters. There’s a lot more to come, as I’ll explain soon in Part II of this series.
-
Test-drive our new site! (And expect âMen at Workâ signs.)
At 2pm on Wednesday, June 17, we opened the doors of Brighter Planet v2.0 to beta testers.
We’ve put our all into this. Risked life and limb, I tell you – courted eyestrain, sleep deprivation, carpal tunnel, general crabbiness. Picture, then, the huge gust of giddy elation that blew through the team when the site went live and didn’t break the entire interwebs! W00t!! Jigs were danced, rafters swung from … I believe the web developers actually emptied the Gatorade jug onto the head of our CTO, Adam.
All this went on for about 10 minutes, and then deep breaths were taken and we all got back to work. We turned on the lights with our to-do list still measured in tonnage – and intentionally so. The reason? We know that you, our eagle-eyed and creative beta testers, will think of things we’d never dream up in a million years – you’ll identify software bugs, solve design problems, and suggest new features that we’re not able to see from our swimming-in-the-soup perspective. We’ll wind up with a smarter, more usable, and ultimately more useful set of tools with you all involved in decisions about where to go from here.
Great feedback has been rolling in from wonderful beta testers like Sarah and Karen. (We can’t thank you guys enough, and are all ears for whatever additional observations you may come up with.) We hope all ye who read this will give the application a whirl and get involved in the dialogue!
Meanwhile, there are crews at work everywhere on the beta site – it’s the web-application equivalent of a skyscraper construction site in there. There are functions that aren’t working quite right, that aren’t yet explained well (blame me – I’m the guy who does most of the ‘splainin’ about how things work), and that simply aren’t ripe. Here’s a round-up of high-priority problems we’ll solve asap and sorely needed features we’re committed to releasing in the near future:
What's Broke:
STUFF WE’RE FIXING IN THE “YOUR FOOTPRINT” CALCULATOR: Our new calculator is the heart of the application, and we’re proud of it – when it’s finished, we’re pretty sure it’ll be the most user-friendly, empowering personal footprint calculator out there. We mean to help you do a complete accounting of your lifestyle’s climate impact, just as the best money-management and weight-management tools help you take inventory in those areas of your life. After you’ve made a good dent in filling it out, you’ll have – cha-ching! – a complete, cruising-altitude view of all you do that has an impact, showing you where there’s real room for improvement, and allowing you to register your accomplishments and track your progress toward a lighter footstep.
So that’s our target for the calculator. At present there are both major and minor things needing fixin’:
- Top priority is resolving our suspicion that the calculator is sometimes outputting inaccurate overall footprints – user feedback and our own observations suggest that some calculations are skewing too high. The calculator’s underlying fundamentals are rock-solid but some data-caching problems we’ve been experiencing could be throwing off the web application’s tabulations. Our credibility depends on providing accurate footprint estimates, and our science and tech teams are working hard on this.
- Also high on the list: bad sums – breakdowns by percentage may not add up to 100; the value displayed for your overall footprint may not match what you get doing your own math adding up the values displayed for your four footprint “components” (Transportation, Shelter, Consumables, Shared Services; etc. Again, data caching issues may be causing the hinky tabulations.
- Another one: say you tell the calculator you drive a Saturn. Next question posed will be “Select your car’s model” – but the list of models you’re asked to choose from are Toyotas, not Saturns. Suspected cause? You guessed it – data caching issues.
- Unwieldy, unalphabetized pulldown lists: “select the airport your flight departed from,” for example. We’re implementing something that will make these much easier to use.
- Opting out of a particular footprint element, e.g. “I don’t [own a car; own a dishwasher; take ferry trips, etc]”: It’s been reported that crossing off one of these isn’t always causing your footprint to be revised downward – it should, and we’re investigating. (Also, please excuse the sometimes truly inelegant phrasing of these – our favorite is “I never occupy residences.”
OTHER STUFF WE’RE FIXIN’:
A grab-bag:
- browser compatibility: We’re trying to resolve some minor weirdness occuring when viewing the site in Safari and Internet Explorer 8. (Note: for now at least, we’re not supporting IE6. We’ll revisit if site traffic suggests that we should.)
- Design ickyness: Throughout the application, some of the forms look fugly, as do some pages in the Carbon Offsets section, and (according to one user) the homepage itself (yipe!). They work (or should, anyway), but aren’t yet pretty. Some just need to be styled properly and we’re confident you’ll like their looks; others – hey, we’ll consider all suggestions; keep ‘em coming.
- In Conservation Tips, clicking “I Did This” is still sometimes producing errors. Most likely, this is happening simply because someone’s doing some work that throws off performance until they’re finished, but we’re investigating.
What’s Coming:
Once these goodies are in place, we’re confident your experience of the site will be slick and fun indeed:
- More depth and granularity in the calculator, especially in the Consumables area. This is a critical one: The goods and services Americans consume are the source of a huge chunk of our individual carbon footprints – and most carbon calculators just sidestep this part of the picture. We want our accounting to consider ALL the lifecycle climate impacts of a person’s lifestyle. My understanding is that while there’s solid data about one’s overall consumables footprint, we’ve got some work to do yet in sourcing and baking into the calculator data about consumables that allows for the same sort of thorough inventory of habits and choices that you’ll experience with, for example, the Transportation-footprint calculator. That’s where we’re headed, for sure, and you’ll see more detail here going forward.
- Analytics / visualizations. Also critical – we want to provide graphs and other visualizations that give you an at-a-glance handle on what’s creating your footprint, how your footprint ranks compared to national (and global) averages, what sort of progress you’re making, and where the low-hanging fruit lies. Just for starters.
- Transparent methodology. Every page of the calculator will allow you to peak under the hood and see what our data sources are and how the calculations are being done.
- More robust privacy options. You’ll be able to decide, in a granular way, what information about yourself and your footprint you want to share with everyone, with just your friends, or with no one.
There are many more, but that’s the short list. Want to leave lots of breathing room for your own ideas to form – if you’re not doing so already, please sign up as a beta tester and start filing feedback if you like!
-
Announcing #earthtweet

We just launched #earthtweet, a campaign to raise awareness of the fight against climate change in the days leading up to Earth Day (April 22) – and beyond.
Here’s the idea: #earthtweet uses Twitter – the booming social network of the moment – to bring together tips, news, information about events, and anything else that’s relevant to solving our climate problem. (Yeah, most of us here at Brighter Planet have caught the Twitter bug – it’s the most useful, vibrant, and fun social network we’ve seen to date.)
If you’re already on Twitter, all you have to do is tell us what you are doing – today – for the planet. Just make sure to use the tag #earthtweet somewhere in each item you’re sharing on Twitter, so everyone else can find it. We’ll also be giving away some eco-friendly prizes throughout the campaign, so follow @earthtweet to stay posted.
If you’re not yet among the converted, this is a perfect opportunity to give Twitter a try. Twitter is like CB radio, but for text messaging – it’s a great way to stay connected to friends, family, and as many other people as you like. Sign up and then you can “follow” @earthtweet and @brighterplanet!
In the last few months we’ve seen people achieve amazing things through collective effort on Twitter. Some examples:
- Two months ago, a group called charity: water issued through Twitter a call for help raising awareness and funds to bring clean drinking water to some of the poorest people in the world. The twitter community responded, organizing fundraisers in more than 200 cities around the world and raising a quarter million dollars for the cause.
- Last Christmas, a TVA coal-burning power plant spilled millions of gallons of toxic coal ash into an East Tennessee river. Advocates on the ground – with support from Twitter folks all over the country – used Twitter to report on the immense scale of the disaster. The buzz grew loud enough that the sluggish national media finally began to cover the story; since then, the Obama administration has made clean-up of thousands of dangerous coal-ash ponds all over the nation part of its agenda.
- PowerShift09 organizers and attendees used Twitter to serve notice that young people are energized and out in force, working to drive the nation toward a clean energy economy.
Well, we want some of that action! We really hope that #earthtweet can make some noise about doing one’s part to solve the climate problem. It’s really up to all of you – #earthtweet will go exactly as far as you take it.
Have a ball with it. You’ll find badges, a widget, and temporary Twitter avatars available at http://earthtweet.com.
-Ian W.
-
350 and still runningâ¦
Well, we did it! After just three and a half weeks, we got over 350 bloggers to participate in the 350 Challenge. We’re so impressed by the way the badge spread from blog to blog, from California to Canada to Turkey … now thousands of readers from all over the world are united through this campaign!
I’d like to share for a minute what 122,500 pounds offset means to us, and our vision of building renewable energy in communities across the United States. While a number can sometimes just seem like a number, 122,500 pounds becomes very real when we help families and communities to build renewable energy - to help sustain their livelihood so that they may do their part to stop the country’s addiction to coal and oil.
To understand the real impact of 122,500 pounds offset, we’ve done some math for everyone. 122,500 pounds offset is like turning off all the power in DC for five minutes, it’s also like making your house off the grid for more than five years!
Due to the success of this campaign, and our commitment to helping spread the word about 350.org we’re going to keep the 350 Challenge going for the time being for any new people that want to post our badge. And we’ll still be donating 350 pounds in their name to our renewable energy projects.

Many, many thanks to everyone who participated!
-
Bring on the 350 Challenge!
We’re really excited to announce the official launch of the 350 Challenge, done in association with our friends at 350.org. The idea is simple: for every blog that posts the 350 Challenge badge, we’ll offset 350 pounds of carbon in their honor. Yep, that’s it!
Our goal is to reach 350 bloggers, which will offset 122,500 pounds of carbon. That’s like turning off the power in Washington, DC for five minutes!
Just click on the badge to get your own. And if you’ve already done it? Thank you.
Who's behind this?
We're Brighter Planet, the world's leading computational sustainability platform.
Who's blogging here?
What are we talking about?
Site generated by jekyll at 2015-05-28 14:08:00 +0000