Safety in Numbers
Brighter Planet's blog
Inferential modeling - fuzzy sets vs. cohorts
Inferential modeling is a big part of our R&D at Brighter Planet. Our impact models are designed to estimate the energy use of some activity without necessarily knowing all the variables that directly drive energy use.
For example, let’s say we want to model the energy use of a modest weekend at the Bellagio in Vegas. We know some information like the local climate and building size, but we don’t know the Bellagio’s exact energy demand. What’s the best way to estimate it?
Basic idea: look at similar properties
A technique we often use in this kind of situation is to cross-reference the information we have with a dataset that includes energy use – in this case the US EIA Commercial Buildings Energy Consumption Survey (CBECS). We find the CBECS records that represent hotels similar to the Bellagio and calculate their average energy intensity.
But what’s ‘similar’?
The big question is how to identify which CBECS records are similar enough to the Bellagio to merit inclusion in our average. There are two basic methods we’ve employed.
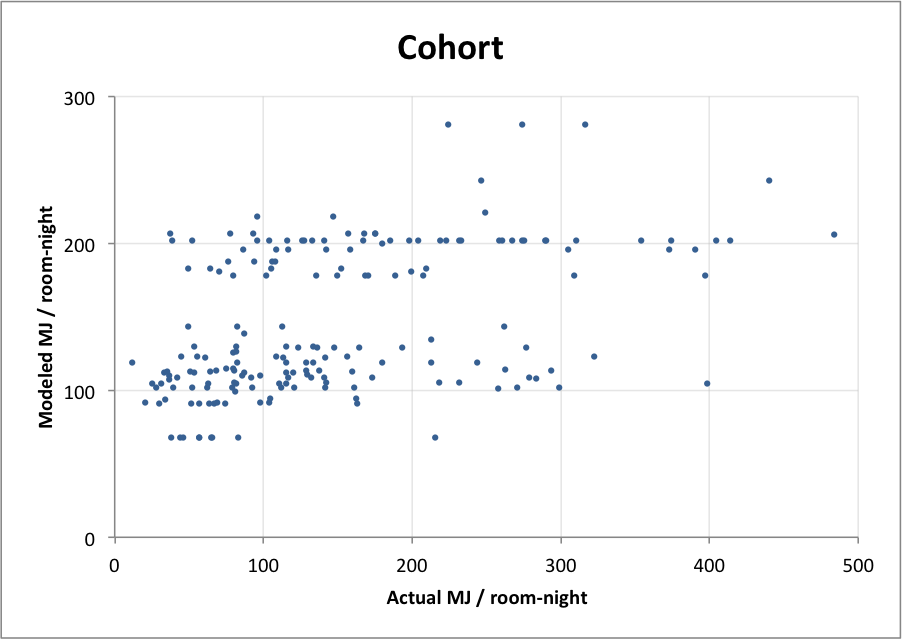
Cohorts
The cohort approach is clean and simple. Using the cohort_analysis gem we filter out all CBECS hotel records that don’t match the Bellagio on key variables. If we’re left with fewer records than a pre-defined minimum sample size we drop the least important variable and re-filter until we have enough records. We then calculate the average energy intensity of those records.
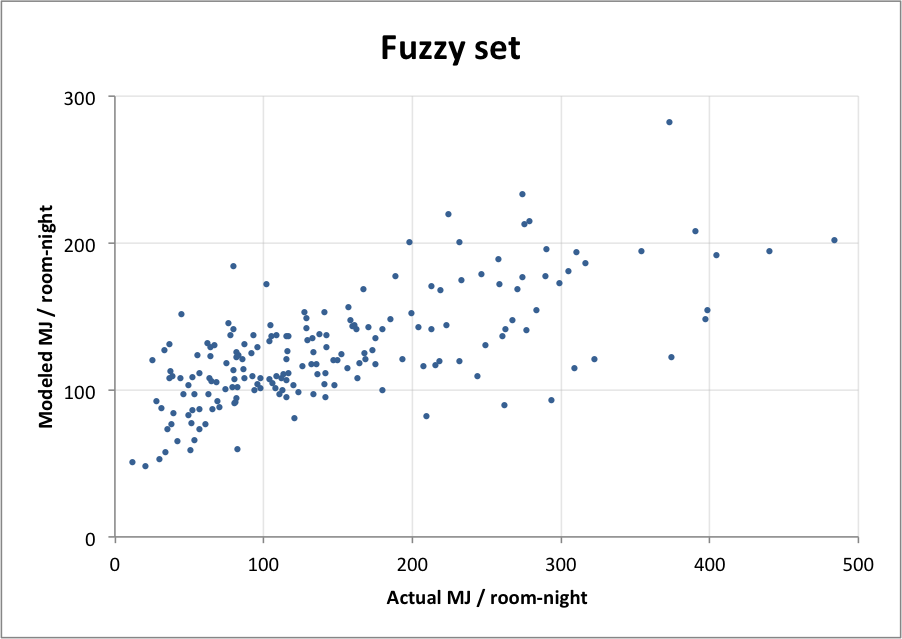
Fuzzy sets
The fuzzy set approach is more nuanced. It recognizes that for continuous variables or when there’s more than one variable a CBECS hotel record isn’t an all-or-nothing match, but rather varies in its degree of similarity. Using the fuzzy_infer gem we assign each record a score for each variable based on how closely it matches the Bellagio. We compile the scores into a “fuzzy weight” and then calculate the average energy intensity across all the records, weighted by their fuzzy weight.
But which is better?
Both approaches follow the same basic profiling idea, but the cohort method is intuitive and faster while the fuzzy set method requires more computation and a lot of statistical tinkering to set up. So is the fuzzy set method really worth all the extra trouble?
We ran some tests, and the answer is definitive.
Fuzzy sets are significantly more accurate
| Cohort | Fuzzy Set | |
|---|---|---|
| Average variation from actual | 68% | 50% |
| Median variation from actual | 43% | 33% |
| Correlation with actual | 0.29 | 0.76 |
What blog is this?
Safety in Numbers is Brighter Planet's blog about climate science, Ruby, Rails, data, transparency, and, well, us.
Who's behind this?
We're Brighter Planet, the world's leading computational sustainability platform.